what even are diffusion models doing ? - part-1
let’s assume we have a prompt and we want to generate some data from it. that data could be an image, audio, video, protein structure, or whatever. but for simplicity, let’s understand everything with images.
assume we want to generate an image vector . to keep the story simple, let’s say we want one image vector for a given prompt .
at a very informal level, we might say:
where is the prompt.
but technically, this is not quite right. a prompt does not usually map to only one fixed image. if i say:
a cat holding a banana
there are infinitely many valid images that could satisfy that prompt. the cat could be orange, black, realistic, cartoonish, sitting, standing, indoors, outdoors, and so on.
so the better way to think about it is not:
but rather:
this means: sample an image from the real distribution of images that match prompt .
so the job of the model is to learn an approximation:
where is the real data distribution and is the model distribution learned by the neural network.
The big goal
neural networks are universal function approximators. so we hope the model can learn a very complicated mapping from prompts and random noise to realistic data.
in a sense, we want the model parameters to capture the distribution of possible images: cats, bananas, humans, cars, lighting, textures, compositions, rare combinations, and even weird stuff like:
a cat holding a banana and dipping it in liquor
the exact event may be extremely rare in the real world. its probability under the real data distribution may be tiny. but if the model has learned the concepts of “cat,” “banana,” “holding,” “dipping,” “glass,” and how objects interact visually, then it can still generate a plausible sample from:
so the model is not just memorizing exact images. it is learning the structure of the image distribution and how language conditions that distribution.
Direct probability matching
the first natural idea is: let’s directly make the model distribution close to the data distribution.
we have:
for the real data distribution, and:
for the model distribution.
the dream is:
or in the prompt-conditioned case:
so we can imagine designing a loss function that measures the mismatch between these two distributions:
the intuition is simple: if the model distribution is far from the real data distribution, the loss is high. if the model distribution matches the real data distribution, the loss is low.
training means changing so that the model’s imagination gets closer to reality.
The problem: probability is too hard
here comes the problem.
estimating the probability of data directly is basically impossible for high-dimensional data like images. a single image is already a massive vector. the number of possible images is beyond imagination.
still, mathematically, we can write a very general model distribution using an energy function:
here, is the energy assigned to image .
low energy means the model thinks the image is realistic.
high energy means the model thinks the image is unrealistic.
the negative sign makes sense:
if the energy is low, this value is high. if the energy is high, this value is low.
so minimizing energy is like maximizing probability.
but this expression needs a normalizing factor:
because probabilities must integrate to .
the normalizing constant is:
i am using instead of here to make the meaning clearer.
this integral says: go over every possible image , compute its unnormalized score , and add everything together.
so the actual probability is:
the numerator asks:
how good is this specific image ?
the denominator asks:
what is the total score of all possible images?
and this is where things break.
computing is intractable because we cannot sum over all possible images. there are simply too many possible ’s.
Autoregressive route
one way around this is the autoregressive way.
in autoregressive models, we break data into pieces and model the joint probability as a product of conditional probabilities:
this is basically what llms do with text. instead of modeling the full sequence all at once, they predict the next token given the previous tokens.
but diffusion takes another route.
Diffusion route: remove the normalizing constant ><
the diffusion route says: instead of directly computing the probability , look at the gradient of the log probability with respect to the data:
this is called the score.
start from the energy-based model:
take log:
now take gradient with respect to :
since depends on the model parameters , not on this particular input , we get:
so:
this is the beautiful trick.
the intractable normalizing constant disappears.
so instead of matching probabilities directly:
we try to match score functions:
the model score tells us something like:
if i slightly move this image vector , which direction makes it more likely under the model?
it is like an arrow pointing toward higher-probability, more realistic regions of image space.
But there is still a problem :(
we got rid of , yes.
but we still do not know:
because we do not know the real data distribution .
we only have samples from it. we have images, but we do not have the formula for the probability landscape of real images.
so diffusion makes a clever detour.
Denoising detour
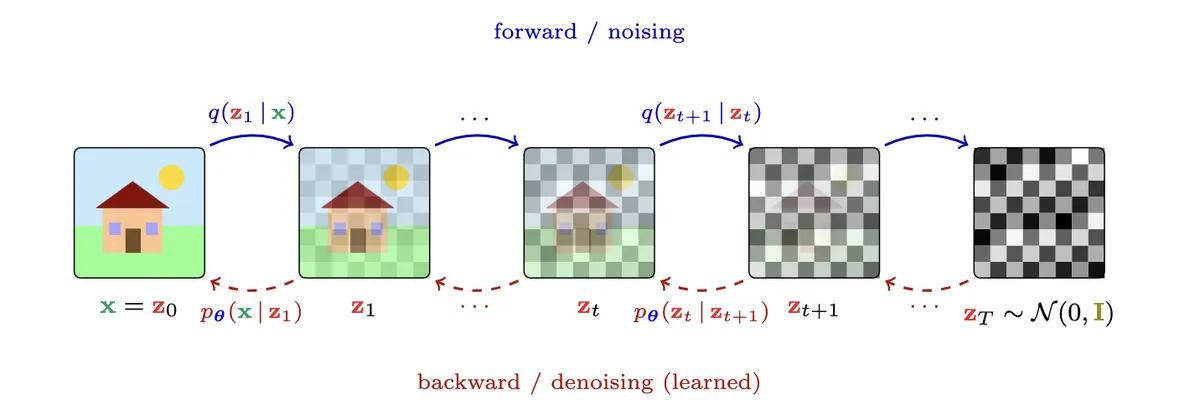
instead of trying to learn the clean data distribution directly, we create a known corruption process.
we take a real training image , add gaussian noise to it, and create a noisy image:
where:
here, is the noise level or timestep.
the coefficient controls how much of the original image remains.
the coefficient controls how much noise is added.
when is small:
so:
the image is almost clean.
when is large:
so:
the image is almost pure gaussian noise.
so we have a forward process:
where is basically gaussian noise.
this noising process is mathematically easy because we designed it ourselves.
the hard part is learning the reverse:
Signal-to-noise ratio
one useful way to understand the noise level is through the signal-to-noise ratio, or snr. since the noisy image is written as:
the term is the remaining real image signal, and the term is the added noise. so the snr is:
if is high, the image still contains a lot of real signal and only a little noise. if is low, the image is mostly noise and only a little signal. people often use the log-snr:
because it is numerically easier to work with. in simple words, snr tells us where we are in the diffusion journey: high snr means close to the clean image, low snr means close to pure gaussian noise.
Training the model
during training, we take real image-prompt pairs:
we sample a random timestep .
we add noise:
then we give the model:
and ask it to predict the noise:
the loss is usually something like:
sometimes the model predicts the clean image , sometimes it predicts the noise , and sometimes it predicts a velocity-like quantity .
but the core idea is the same:
the model learns how to denoise.
How this learns the data distribution
now the key question:
how does denoising approximate ?
if you take all real images:
and you add gaussian noise at time , you get a new distribution:
this is the distribution of noisy real images at noise level .
at , this distribution is basically the real data distribution:
at large , this distribution becomes close to pure gaussian noise:
so diffusion builds a bridge:
training teaches the model how to walk backward across this bridge.
if the model learns the reverse denoising direction correctly for every timestep, then at generation time we can start from pure noise:
and repeatedly denoise:
at the end, should look like a real image:
and ideally:
in the prompt-conditioned case:
The important intuition
the model is not learning one fixed mapping from one noisy image to one clean image.
for every image, there are infinitely many possible noisy versions because every noise sample is different.
also, at high noise levels, one noisy point could be consistent with many possible clean images.
so this is not a one-to-one mapping.
what the model really learns is a denoising field:
given a noisy point , a time , and a prompt , which direction should we move to become more like realistic data matching that prompt?
you are giving the model billions of broken pictures that you broke in a mathematically controlled way.
then you ask it again and again:
what was the noise?
or:
how do i get back to the clean image?
after seeing enough examples, the model generalizes. it learns the structure of real images, the structure of language, and the relationship between prompts and images.
then at inference time, you give it pure noise plus a prompt, and it gradually sculpts the noise into an image that belongs to the learned conditional distribution.
Final picture
the final generation process is:
more formally:
and the whole training goal is: